LangManus从入坑到放弃
一、背景
最近老是刷到说国内某大厂复刻了一个Manus,并且还开源了。我心想既然是大厂出品,那多多少少还有几把刷子在里面的,于是就打算下载下来试试,看看效果如何。
这不下不知道,一下吓一跳,刚开始就差点给我劝退了;因为我在克隆项目的时候,老是卡在20%左右的进度,起初我还以为是我网络的问题,后面施加了一点小法术,还是卡在了20%左右,再后来我就没管了,让子弹先飞一会儿。结果你们猜咋了,整个项目大小157.5M,我滴个乖乖,这里面都有些啥啊,这么大!!!

本着好奇害死猫的想法,我进一步查了历史提交记录,发现提交了一个演示视频,作者直接放代码仓库里面提交上去了,后来发现太大了,删除了,重新压缩了一下。
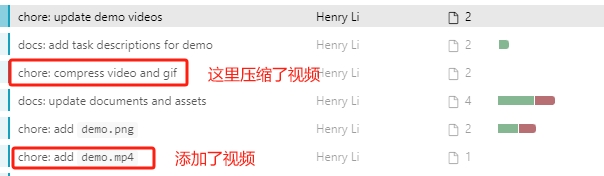
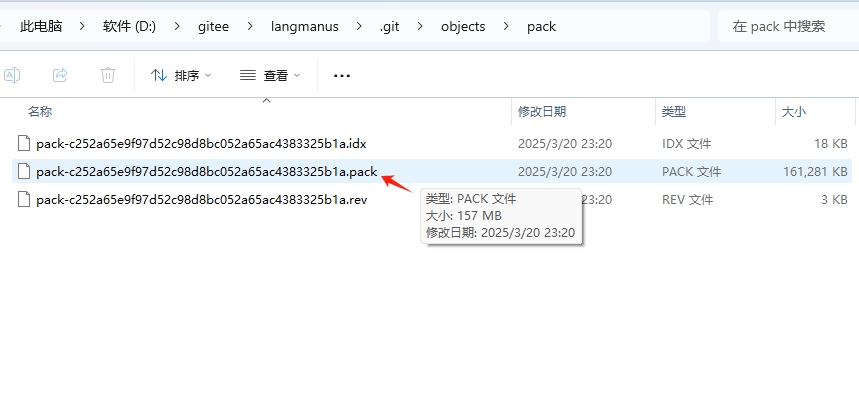
接着我又查了一下我本地的**.git文件夹,发现了一个157M大小的文件,一般情况下.git/objects/pack** 文件过大,可能是由于开发过程中上传过大文件,虽然现已删除,但仍然保存着git记录中,这基本上验证了我的猜想,所以后面的朋友建议直接下载压缩包,以免浪费时间。
five years ago 。。。
嗯。。。,没事儿,好歹是把代码克隆下来了,大点就大点,好用就行。接下就是按照官方步骤来操作了(本文是基于Windows11操作系统环境来编写的)。
二、安装配置
环境准备,先安装node 20+和python3.12
具体步骤请咨询AI!!!
UV安装
# 第一种方式直接安装
# uv安装,官网:https://docs.astral.sh/uv/#installation
# 在poweshell终端执行如下命令
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
# 第二种方式
pip install uv安装完成后,在C:\Users\你用户名\AppData\Roaming\uv,配置国内源
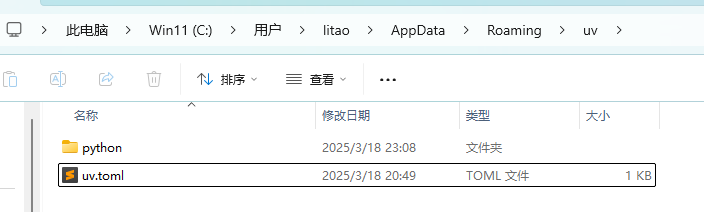
uv.toml
index-url="https://mirrors.aliyun.com/pypi/simple"项目编译
# 安装依赖
uv sync
# Playwright install to use Chromium for browser-use by default
uv run playwright install配置模型,密钥等资源,切记不要乱改模型和服务商,咱就乖乖的用官方的例子
复制.env.example并重命名为.env,在这里我也踩了一些坑,我把服务换成了硅基流动的,结果可想而知,跑不起来,根本跑不起来,所以还是老老实实的换成了官方的配置,具体**.env**配置如下:
# LLM Environment variables
# 推理 LLM 配置(用于复杂推理任务)
REASONING_MODEL=deepseek-r1
REASONING_API_KEY=sk-密钥
REASONING_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
# 基础 LLM 配置(用于简单任务)
BASIC_MODEL=qwen-max-latest
BASIC_API_KEY=sk-密钥
BASIC_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
# 视觉语言 LLM 配置(用于涉及图像的任务)
VL_MODEL=qwen2.5-vl-72b-instruct
VL_API_KEY=sk-密钥
VL_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
# 工具 API 密钥
TAVILY_API_KEY=tvly-密钥
# Application Settings
DEBUG=True
APP_ENV=development
# turn off for collecting anonymous usage information
ANONYMIZED_TELEMETRY=false以上配置需要用到的密钥注册地址:
阿里百炼:https://www.aliyun.com/product/bailian
Tavily:https://tavily.com/
以上步骤弄完了就可以运行项目了
# 在终端执行如下命令
uv run main.py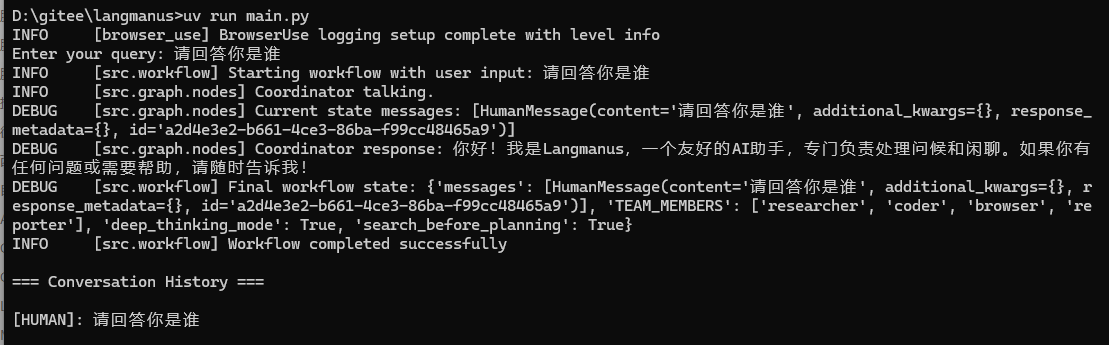
运行成功,没毛病!
三、前端项目
LangManus还贴心的提供了前端项目,地址:https://github.com/langmanus/langmanus-web ,这就简单了,按如下操作就行!
复制.env.example并重命名为.env,内容不用修改,就这一条
NEXT_PUBLIC_API_URL=http://localhost:8000/api编译代码并运行
# 安装依赖
npm install
# 运行前端项目
npm run dev
# 在langmanus文件夹下运行后端项目
uv run server.py
出现以上界面就表示项目运行成功了!
四、测试演练
打开http://localhost:3000/ 发现界面还可以!
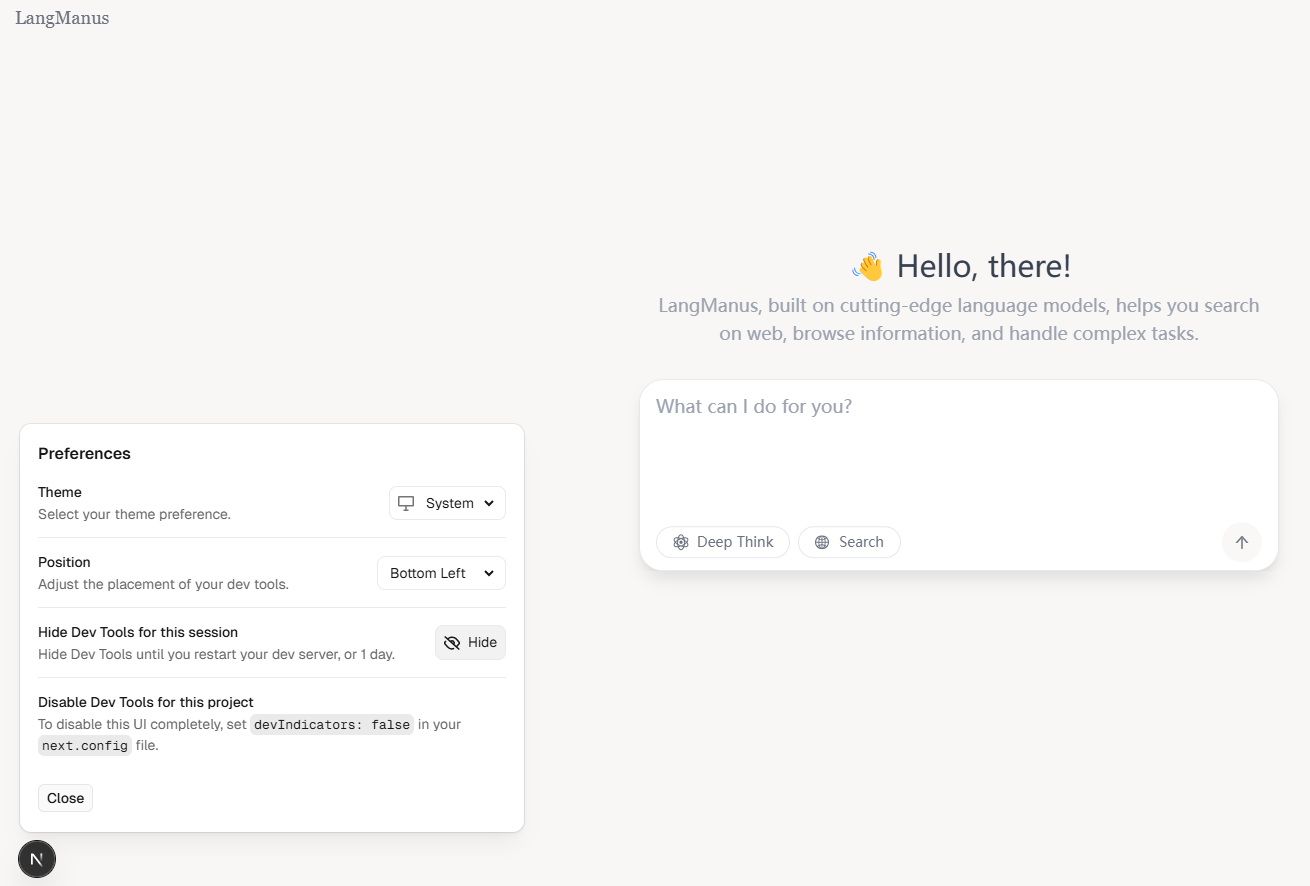
接下来我们来问一个老问题,让他“统计豆瓣TOP10的电影名称“
效果还挺惊艳的。。。
但是结果好像不是那么肥四鹅。。。
LangManus的结果(让我奇怪的是,我运行了多次,每一次结果都不一样。。。):

我自己查的结果:

鹅,这个怎么说了,可能跟统计维度有关系,毕竟我给的条件也不是那么精确。整体看起来是不错,就是在模型兼容那方面可能还有点问题,社区活跃度没有OpenManus那么高,只能说加油,期待下一个版本亮瞎各位的双眼。
关注我,了解更多AI黑科技