自媒体人的数据福音!MediaCrawler:让内容创作者不再"大海捞针"
📢 还在为每天手动搜索热点、整理素材而疲于奔命?MediaCrawler——这款被誉为"自媒体人数据助手"的神器,能帮你精准捕获全网优质内容,彻底告别低效的内容采集方式! 它是一个功能强大的多平台自媒体数据采集工具,支持小红书、抖音、快手、B站、微博、贴吧、知乎等主流平台的公开信息抓取。
🔍 为什么说它是内容创作者的"数据福音"?
🕵️♂️ 痛点扫描
- 每天3小时找素材,真正创作时间不足1小时
- 热点总是慢人一步,错过最佳发布时间
- 优质内容散落各处,难以系统化管理
- 竞品分析靠手动记录,效率低下
✨ MediaCrawler的四大核心价值
⏳ 时间压缩器 自动采集替代人工搜索,节省70%素材收集时间
🚀 热点加速器 实时追踪100+平台爆文,智能预测内容趋势
📊 数据透视镜 深度分析10w+竞品内容,生成可视化运营报告
🗃️ 智能素材库 自动归档分类,建立个人专属内容资源中心
🛠️ 实战教程:两步玩转MediaCrawler
1️⃣ 环境准备
sh
# 克隆代码
git clone https://github.com/NanmiCoder/MediaCrawler.gitsh
# 安装依赖库
pip install -r requirements.txtsh
# 安装 playwright浏览器驱动
playwright install
2️⃣ 运行爬虫
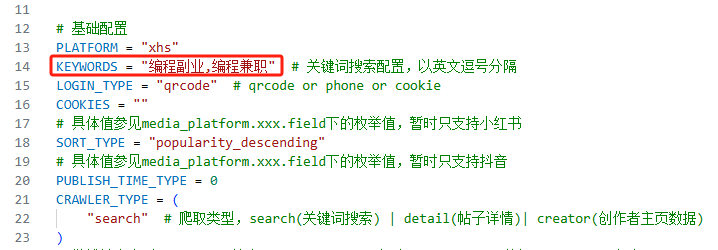
修改base_config.py里面的KEYWORDS,改成自己想要查询的关键字
python
# 执行命令,开始爬取小红书,结果默认是以json形式存放在data文件下面
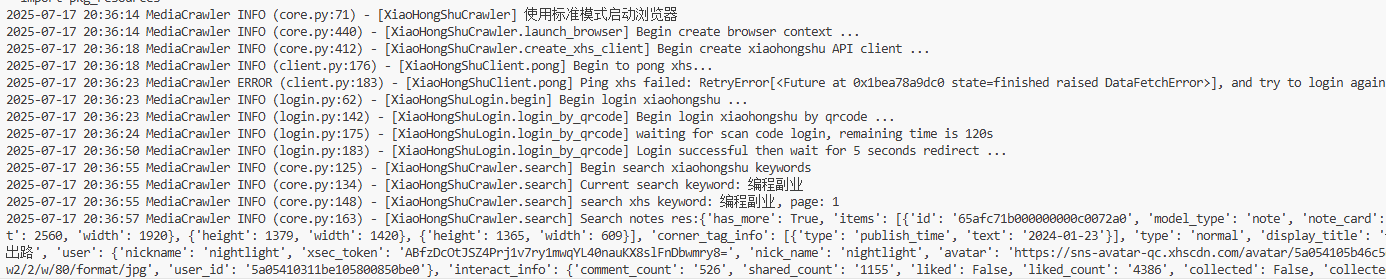
python main.py --platform xhs --lt qrcode --type search会弹出浏览器,要求你扫码登录,然后就开始爬取数据了
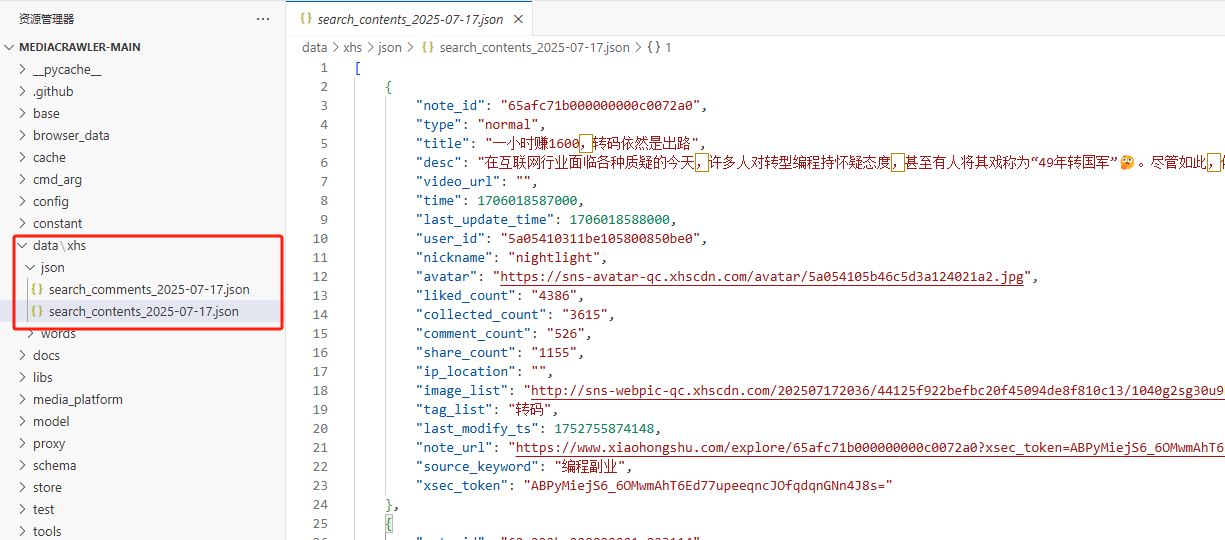
然后你就会在data文件夹下面看看爬取的数据了
💡 使用技巧
- 🔎 关键词优化:使用"长尾词+热点词"组合
- ⏱ 定时采集:设置凌晨自动运行
- 🛡️ 防封策略:合理设置采集间隔
- 🧹 数据清洗:内置智能去重算法
⚠️ 注意事项
- 遵守各平台robots协议
- 合理设置采集频率
- 尊重原创,仅作分析参考
- 建议搭配VPN使用
- 遵纪守法,不乱爬东西
📌 总结:MediaCrawler不是万能的,但确实能帮你把"找素材"这件苦差事变得轻松高效。