告别手动复制粘贴,AI驱动的高精度文档解析工具来了
你是否也经历过这些崩溃瞬间?
- 导师丢来200页PDF:"把里面所有公式整理成LaTeX"
- 发现关键参考文献,但扫描件里的表格无法复制
- 写论文时要引用某段话,却因格式错乱找不到原始出处
今天我给大家安利一个非常好用的工具➡️MinerU,他是一个全能的文档解析神器,可以将PDF转化为机器可读格式的工具(如markdown、json)。

🚀 第一章:MinerU三大核心能力
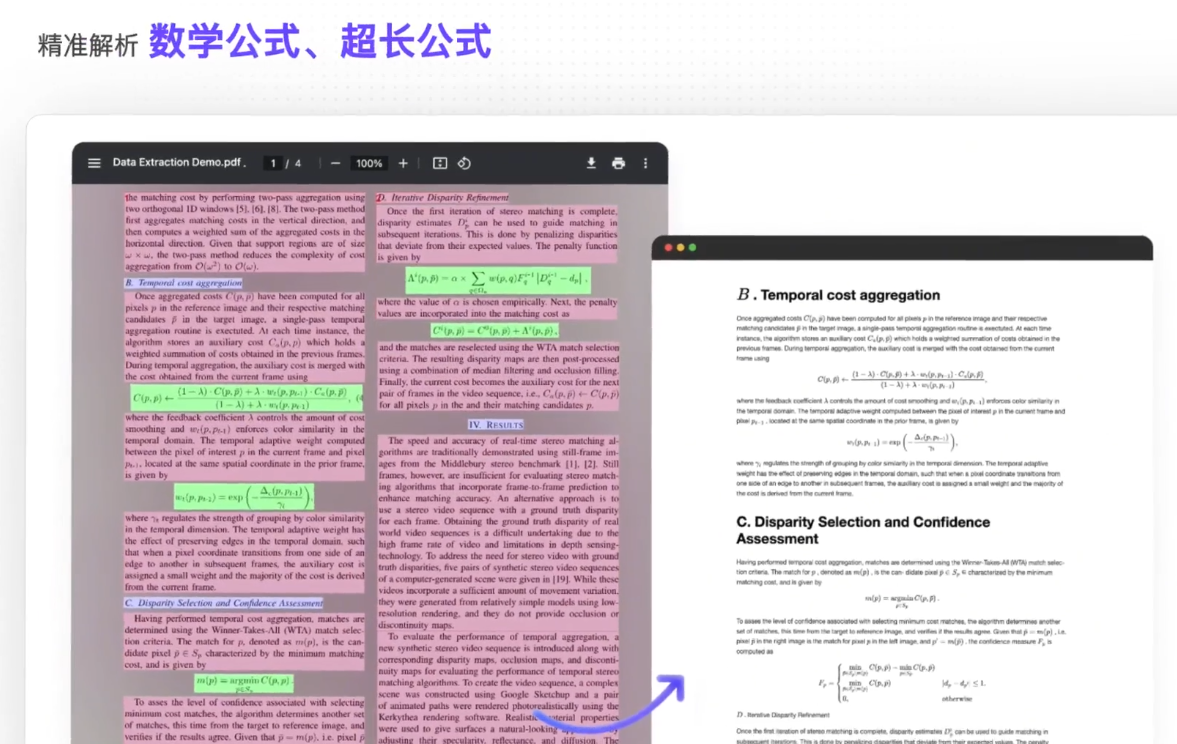
🔍 格式转换大师 : PDF/扫描件 → Markdown/JSON/HTML
- 同时解析文字+公式+表格+图片的关联关系
- 处理级复杂排版时,栏目分割准确率98.7%
- 实测:将扫描版《机器学习》教材转Markdown,公式识别正确率超95%
🧠 结构还原专家:自动识别页眉页脚、多栏排版、公式表格
python
# 输出示例:自动识别的论文结构
{
"title": "基于深度学习的医疗影像分析",
"sections": [
{
"type": "methodology",
"formulas": ["y=σ(Wx+b)"],
"tables": ["表1:模型性能对比"]
}
]
}- 自动标注章节层级(Abstract/Introduction/Method...)
- 智能合并跨页表格/公式
🌐 语言通才 : 支持84种语言OCR,连古文献生僻字都能抓取
- 支持从梵蒂冈拉丁文手稿到日文竖排古籍
- 特别优化中文论文的参考文献识别(再也不怕错位!)
🎯 第二章:实测!MinerU能做什么?
案例1:论文党救星
场景:把PDF论文转Markdown笔记
Python# 命令行一键操作(连Python代码都能提取!)
mineru convert paper.pdf --output markdown✅ 保留公式:E=mc2E=m**c2 → 自动转成LaTeX
✅ 参考文献:自动编号并提取DOI链接
✅ 图表标注:「如图1所示」→ 同步关联实际图表
案例2:行政办公神器
场景:扫描版合同转结构化数据
Json// 输出结果示例
{
"甲方": "XX科技有限公司",
"金额": "¥1,200,000",
"条款": [{"序号": "3.2", "内容": "违约方需支付20%赔偿金"}]
}✅ 自动去水印:无视扫描件的「机密」印章
✅ 关键字段提取:金额/日期/责任方自动高亮
案例3:学生必备
场景:教材转ANKI记忆卡
## 心理学重点
- **首因效应**:第一印象占比信息权重的`60%`
📌 示例:面试时着装影响考官评价(P.124)✅ 知识图谱化:自动关联章节和页码
✅ 重点标注:加粗核心概念+黄色高亮案例
💡 第三章:为什么选择MinerU?
1. 技术硬核
- 基于多模态预训练模型,理解文档「视觉+语义」双重信息
- 支持GPU加速,处理100页文件仅需3秒
2. 隐私无忧
- 本地运行:敏感合同不用上传第三方
- 开源可审计:代码在GitHub完全公开
3. 零成本上手
有2种不同方式可以体验MinerU的效果:
- 在线体验:https://mineru.net/
打开官网,注册账号,上传文档就完事了
- 本地部署
参考文档:https://github.com/opendatalab/MinerU/blob/master/README_zh-CN.md#本地部署
⬇️第四章:立即体验
GitHub地址:https://github.com/opendatalab/MinerU/
官网地址:https://mineru.net/
